DDD implements the idea of Domain Driven Disambiguation. It exploits the Domain Labels (e.g. Medicine, Sport, Architecture) associated to the WordNet synsets provided by the lexical resource WordNet Domains. For each word to disambiguate, a "domain vector" describing the domain of the context is estimated. Then it is compared with the domain vectors for each word sense, and the most similar one is selected. When provided by the lexical resource, the DDD system exploits information about sense frequency. Methodologically DDD does not take into account any syntagmatic information. DDD does not require any sense labeled data, then it can be used for "all-words" tasks.
 The DDD framework is now integrated by syntagmatic information in the Kernel-WSD system. Kernel-WSD was the best performing system in many SENSEVAL-3 lexical sample tasks.
The DDD framework is now integrated by syntagmatic information in the Kernel-WSD system. Kernel-WSD was the best performing system in many SENSEVAL-3 lexical sample tasks.
The DDD framework is now integrated by syntagmatic information in the Kernel-WSD system. Kernel-WSD was the best performing system in many SENSEVAL-3 lexical sample tasks.
Systems
DDD.0
Presented at SENSEVAL-2 (2001) competition.
-
• English Lexical Sample
-
• English All Words
-
• Italian Lexical Sample
DDD.1
Developed in the context of the MEANING European
project. It has been exploited to disambiguate English, Italian and Spanish texts.
Improvements:
Improvements:
-
• Multiword expressions are identified
-
• Robustness
-
• Portability among languages
DDD.2
Presented at the SENSEVAL-3 (2004) competition in the English all-words task.
Improvements:
Improvements:
-
•The Gaussian Mixture Algorithm for Domain Relevance Estimation has been adopted to estimate the domain of the context of the word to disambiguate.
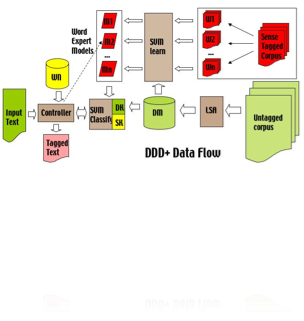
The DDD systems
